Xarxes neuronals
- Origen i justificació
- El perceptró
- Xarxa neuronal bàsica
- Arquitectura d’una xarxa
- Propagació cap endavant
- Entrenament de xarxes neuronals
- Funcions d’activació
- Classificació multiclasse
- Classificació multietiqueta (multilabel)
- Pytorch per tipus de problema
- Optimització avançada
- Grafs computacionals i diferenciació automàtica
- L’arquitectura Transformer i els LLMs
- Capes convolucionals
- Càlcul eficient per a xarxes neuronals
Origen i justificació
Les xarxes neuronals són una branca de l’aprenentatge automàtic inspirada en l’estructura i el funcionament del cervell biològic. El seu desenvolupament inicial es va centrar en aplicacions com el reconeixement de la parla, el reconeixement d’imatges i el processament del llenguatge natural (PLN). Amb el temps, aquestes tècniques van evolucionar cap al que avui coneixem com aprenentatge profund (deep learning), que destaca per la utilització de xarxes neuronals amb moltes capes capaces d’aprendre representacions complexes a partir de grans volums de dades.

Amb l’arribada de les xarxes neuronals profundes, l’estructura del pipeline de treball en l’aprenentatge automàtic ha canviat profundament. Mentre que els models tradicionals requereixen una fase prèvia de selecció i disseny manual de característiques (feature engineering), les xarxes neuronals tenen la capacitat d’aprendre representacions útils directament a partir de dades en brut —com imatges, àudio o text sense processar. Això simplifica el desenvolupament de models i permet construir sistemes molt més potents en tasques complexes com la visió per computador, el reconeixement de veu o la traducció automàtica.
Una de les raons fonamentals per les quals aquestes xarxes són tan efectives és la seva capacitat d’escalar amb dades. Escalar, en aquest context, vol dir que el model pot millorar progressivament el seu rendiment a mesura que augmenta la quantitat de dades disponibles. A diferència d’algorismes com la regressió lineal o la regressió logística, que tenen una capacitat d’aprenentatge limitada i sovint no es beneficien de grans volums de dades, les xarxes neuronals poden seguir aprenent patrons més rics i complexos a mesura que se les alimenta amb més informació.
Aquest comportament és possible perquè les xarxes neuronals aprenen representacions internes cada cop més sofisticades, que permeten capturar estructures i relacions profundes dins les dades. Aquestes representacions són la clau per a una millor generalització i per a la creació de models més robustos. La combinació d’aquesta capacitat d’aprenentatge escalable amb l’ús de maquinari especialitzat com les GPU ha estat determinant en l’avenç dels sistemes d’intel·ligència artificial en la darrera dècada.
El perceptró
Abans d’explorar xarxes neuronals complexes, cal entendre l’element bàsic: el perceptró, un model matemàtic inspirat en la neurona biològica proposat per Frank Rosenblatt el 1957.
Funcionament del perceptró
Un perceptró és una unitat computacional simple que imita el comportament d’una neurona: rep múltiples senyals d’entrada, les pondera segons la seva importància, i produeix una sortida binària en funció d’un llindar.
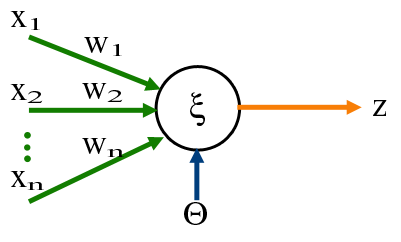
Un perceptró realitza les operacions següents:
- Rep múltiples entrades: \(x_1, x_2, \ldots, x_n\)
- Multiplica cada entrada pel seu pes: cada entrada \(x_i\) té un pes associat \(w_i\) que indica la seva importància
- Suma tots els productes i afegeix un biaix: calcula \(z = w_1x_1 + w_2x_2 + \cdots + w_nx_n + b\)
- Aplica una funció d’activació: transforma \(z\) en una sortida \(\hat{y}\)
Matemàticament, podem expressar-ho com:
\[ z = \mathbf{w} \cdot \mathbf{x} + b = \sum_{i=1}^{n} w_i x_i + b \]
\[ \hat{y} = g(z) \]
on \(g\) és la funció d’activació. El perceptró original utilitzava una funció esglaó (step function):
\[ g(z) = \begin{cases} 1, & \text{si } z \geq 0 \\ 0, & \text{si } z < 0 \end{cases} \]
Aquesta funció converteix la combinació lineal ponderada en una decisió binària: activa (1) o inactiva (0).
El perceptró defineix un hiperplà de decisió en l’espai d’entrades. L’equació \(\mathbf{w} \cdot \mathbf{x} + b = 0\) representa aquest hiperplà:
- Els punts on \(\mathbf{w} \cdot \mathbf{x} + b \geq 0\) es classifiquen com a classe 1
- Els punts on \(\mathbf{w} \cdot \mathbf{x} + b < 0\) es classifiquen com a classe 0
En dues dimensions, aquest hiperplà és una línia recta; en tres dimensions, un pla.
Limitació i evolució
El perceptró pot aprendre a separar classes linealment separables, però té una limitació fonamental: no pot resoldre problemes no lineals com el famosa porta lògica XOR.
Aquesta limitació va motivar el desenvolupament de les xarxes neuronals multicapa, que combinen múltiples unitats de processament en capes per aprendre relacions no lineals complexes.
Les xarxes neuronals actuals utilitzen una generalització del perceptró que anomenem neurona artificial (o simplement “neurona”). Vegem les similituds i diferències:
Similituds amb el perceptró:
- Rep múltiples entrades ponderades per pesos \(w_i\)
- Suma les entrades amb un biaix \(b\)
- Aplica una funció d’activació \(g(z)\)
Diferències clau:
- Utilitza funcions d’activació diferenciables (sigmoide, ReLU, tanh) en lloc de la funció esglaó
- Això permet l’entrenament amb retropropagació i descens de gradient, que requereixen derivades
- És un concepte més flexible i general
Terminologia:
- Perceptró: model històric específic amb funció esglaó (Rosenblatt, 1957)
- Neurona artificial: unitat bàsica de les xarxes neuronals modernes, generalització diferenciable del perceptró
D’ara endavant, quan parlem de xarxes neuronals, utilitzarem el terme “neurona” per referir-nos a aquestes unitats modernes que generalitzen el concepte original del perceptró. El perceptró és la pedra angular històrica sobre la qual es construeixen les arquitectures modernes d’aprenentatge profund.
Xarxa neuronal bàsica
Com hem vist, el perceptró clàssic té limitacions importants: només pot aprendre patrons linealment separables. Per superar aquesta limitació, combinem múltiples neurones artificials organitzades en capes, creant així una xarxa neuronal. Aquestes neurones utilitzen funcions d’activació diferenciables (no la funció esglaó del perceptró clàssic), cosa que permet a la xarxa aprendre representacions no lineals complexes mitjançant un procés d’aprenentatge anomenat retropropagació que veurem més endavant.
Vegem un exemple pràctic per entendre com funciona una xarxa neuronal amb capes.
Suposem que volem predir si un producte tindrà una alta demanda. La sortida de la xarxa serà la probabilitat que esdevingui un supervendes.

- Característiques d’entrada: preu, cost d’enviament, esforç de màrqueting, material.
- Capa d’entrada: rep aquests quatre valors sense fer cap càlcul. És una capa estructural.
- Capa oculta: calcula característiques de nivell més alt, també anomenades activacions, aprenent a donar més importància a certes entrades, com per exemple:
- Assequibilitat (a partir de preu i enviament)
- Coneixement del producte (a partir de màrqueting)
- Qualitat percebuda (a partir de preu i material)
- Capa de sortida: rep els valors de la capa oculta i retorna un únic número: la probabilitat estimada.
Les capes situades entre l’entrada i la sortida s’anomenen capes ocultes perquè no interactuen directament amb les dades d’entrada ni amb la sortida final, sinó que aprenen representacions intermèdies útils per resoldre la tasca.
L’arquitectura d’aquesta xarxa és [4-3-1] de dues capes (no comptem la d’entrada) i de tipus feedforward (sense connexions cap enrere).
Tot i que el diagrama només mostra algunes connexions per claredat visual, aquesta és una xarxa totalment connectada o densa (fully connected o dense layer). Això significa que cada neurona de la capa oculta està connectada a totes les 4 entrades, i la neurona de sortida està connectada a totes les 3 neurones de la capa oculta. En total, hi ha:
- 4 × 3 = 12 connexions entre l’entrada i la capa oculta
- 3 × 1 = 3 connexions entre la capa oculta i la sortida
Cada connexió té un pes associat, i cada neurona té un biaix. Per tant, el nombre total de paràmetres entrenables d’aquesta xarxa és:
- Capa oculta: 12 pesos + 3 biaixos = 15 paràmetres
- Capa de sortida: 3 pesos + 1 biaix = 4 paràmetres
- Total: 19 paràmetres
Cadascuna de les característiques de la capa oculta (assequibilitat, coneixement, qualitat) és calculada per una neurona independent. Per exemple, la neurona d’“assequibilitat” rep com a entrades el preu i el cost d’enviament, els multiplica pels seus pesos aprenuts \(w_1\) i \(w_2\), suma el biaix \(b\), i aplica una funció d’activació (com ara sigmoide o ReLU) per produir un valor d’activació. Així, una xarxa neuronal està formada per múltiples neurones treballant en paral·lel dins de cada capa, cadascuna aprenent a detectar patrons específics de les dades.
En el ML tradicional, les característiques rellevants es dissenyen a mà. Però en una xarxa neuronal general, cada neurona d’una capa rep totes les sortides de la capa anterior. Això permet que la xarxa aprengui quines característiques són importants, ajustant els pesos de connexió.
Recordem que cada neurona dins d’una capa utilitza els mateixos elements que hem vist al perceptró:
- Pesos (\(w\)): indiquen la importància de cada entrada que rep la neurona.
- Biaix (\(b\)): un valor addicional que permet desplaçar l’activació amunt o avall, fins i tot quan totes les entrades són zero. Sense el biaix, la neurona estaria obligada a passar sempre per l’origen i tindria menys flexibilitat per ajustar-se a les dades.
Cada capa transforma les activacions \(a^{[i]}\) d’entrada en activacions de sortida mitjançant el mateix procés que al perceptró: combinació lineal ponderada seguida d’una funció d’activació diferenciable.
Aquest procés es repeteix capa rere capa fins a obtenir la sortida final (per exemple, un escalar en regressió):
\[ x \rightarrow a^{[1]} \rightarrow a^{[2]} \rightarrow \dots \rightarrow \hat{y} \]
Intuïció: en aquest exemple, si ignorem la capa d’entrada, podríem interpretar la xarxa com una regressió logística amb tres entrades, més apropiades que les quatre originals. És com si la xarxa ens fes enginyeria de característiques automàticament.
Arquitectura d’una xarxa
Per construir una xarxa neuronal, cal decidir:
- Quantes capes ocultes tindrà
- Quantes neurones per capa
Aquestes decisions defineixen l’arquitectura de la xarxa. Una arquitectura típica és el perceptró multicapa (Multilayer Perceptron o MLP, un nom històric que s’ha mantingut, malgrat que les seves unitats són neurones modernes amb funcions d’activació diferenciables).
Important sobre el recompte de capes: Quan descrivim una arquitectura, normalment no comptem la capa d’entrada ja que aquesta no fa cap transformació de les dades. Per exemple, una xarxa amb arquitectura [64-25-15-1] té 3 capes entrenables: dues capes ocultes (25 i 15 neurones) i una capa de sortida (1 neurona). La capa d’entrada (64 valors) només passa les dades a la primera capa oculta.
Imaginem una imatge en escala de grisos de 1000×1000 píxels (1 milió de valors). Aplanar la matriu ens dona un vector d’entrada amb 1.000.000 valors.
- Entrada: els valors de brillantor dels píxels (entre 0 i 255)
- Sortida: la probabilitat que la cara sigui de la persona “XYZ”
Què aprèn la xarxa?
- Capa baixa: detecta vores i línies
- Capa intermèdia: reconeix regions facials
- Capa alta: identifica cares completes

Les capes van combinant les representacions detectades segons ens aproximem a la sortida. S’anomenen representacions jeràrquiques, i són descobertes automàticament durant l’entrenament.
Propagació cap endavant
La propagació cap endavant (forward propagation) és el procés pel qual una xarxa neuronal transforma les dades d’entrada en una predicció. És com una cadena de transformacions: cada capa processa la informació que rep de l’anterior i la passa a la següent.
S’utilitza en dues fases:
- A l’entrenament, per calcular la sortida i la seva pèrdua.
- A l’inferència, per calcular la sortida i generar prediccions.
Per exemple, imagina que vols reconèixer si una imatge de 8×8 píxels és un “0” o un “1”:
- Entrada: Els 64 píxels (aplanats en un vector) entren a la xarxa
- Primera capa: Les neurones detecten patrons simples (vores, línies)
- Segona capa: Combina els patrons anteriors en formes més complexes
- Sortida: Una neurona final decideix: “Això és un 1” (o un 0)
Cada capa transforma les dades aplicant pesos, sumant biaixos, i passant el resultat per una funció d’activació (com sigmoide o ReLU).
Per a cada neurona d’una capa:
- Combina les entrades: Multiplica cada valor que rep pel seu pes corresponent i suma-ho tot
- Afegeix el biaix: Suma un valor extra que permet ajustar la sortida
- Aplica l’activació: Transforma el resultat amb una funció no lineal
Matemàticament, per una neurona:
\[ z = w_1 x_1 + w_2 x_2 + \cdots + w_n x_n + b \]
\[ a = g(z) \]
On \(g\) és la funció d’activació, que introdueix no linealitat al model.
Una de les funcions d’activació més clàssiques és la sigmoide, definida com:
\[ \sigma(z) = \frac{1}{1 + e^{-z}} \]
Aquestes són les seves característiques principals:
- Sortida entre 0 i 1: Ideal per interpretar com a probabilitats
- Suau i diferenciable: Necessari per poder entrenar la xarxa
- No lineal: Permet a la xarxa aprendre patrons complexos
Per exemple, si \(z = 0\), llavors \(\sigma(0) = 0.5\). Si \(z\) és molt positiu (per exemple, \(z = 5\)), \(\sigma(5) \approx 0.993\). Si \(z\) és molt negatiu (per exemple, \(z = -5\)), \(\sigma(-5) \approx 0.007\).
Més endavant veurem altres funcions d’activació com ReLU, però de moment utilitzarem sigmoide per la seva simplicitat i interpretabilitat.
Exemple: Reconèixer dígits 0 vs. 1
Considerem una xarxa amb aquesta arquitectura:
- Entrada: 64 valors (imatge 8×8 aplanada)
- Capa oculta 1: 25 neurones amb activació sigmoide
- Capa oculta 2: 15 neurones amb activació sigmoide
- Sortida: 1 neurona amb sigmoide (probabilitat de ser “1”)
La xarxa processa així, aplicant la funció sigmoide \(\sigma\) a cada capa:
\[ a^{(1)} = \sigma(W^{(1)} x + b^{(1)}) \]
\[ a^{(2)} = \sigma(W^{(2)} a^{(1)} + b^{(2)}) \]
\[ \hat{y} = \sigma(W^{(3)} a^{(2)} + b^{(3)}) \]
El valor final \(\hat{y}\) (entre 0 i 1) representa la probabilitat que la imatge sigui un “1”. Si \(\hat{y} \geq 0.5\), classifiquem la imatge com a “1”; altrament, com a “0”.
Inferència: fer prediccions
Un cop la xarxa està entrenada, fer una predicció és simplement aplicar la propagació cap endavant. En la pràctica, processem múltiples mostres alhora en lots (batches) per guanyar eficiència:
import torch
# Xarxa ja entrenada
model = ThreeLayerNN()
model.eval() # Mode d'avaluació
# Predicció amb una sola mostra
x = torch.randn(1, 64) # 1 mostra, 64 píxels
with torch.no_grad():
y_pred = model(x)
print(f"Probabilitat: {y_pred.item():.2f}")
# Predicció amb un lot de mostres (més eficient)
X = torch.randn(10, 64) # 10 mostres, 64 píxels cada una
with torch.no_grad():
y_pred_batch = model(X) # 10 prediccions en paral·lel
Internament, PyTorch utilitza operacions matricials que permeten calcular totes les prediccions simultàniament, aprofitant biblioteques optimitzades (BLAS a CPU o cuBLAS a GPU). Això és molt més ràpid que processar cada mostra individualment.
En resum: La propagació cap endavant és una sèrie de transformacions lineals (pesos + biaixos) seguides de funcions no lineals (activacions), capa rere capa, fins a obtenir la predicció final.
Entrenament de xarxes neuronals
L’entrenament d’una xarxa neuronal es fa habitualment en tres passos fonamentals:
- Definició del model
- Definició de la funció de pèrdua i cost
- Entrenament per a minimitzar el cost
Definició del model
Com es calcula la sortida a partir de l’entrada?
Cal especificar com el model calcula la sortida \(\hat{y}\) a partir de les dades d’entrada \(x\), utilitzant els paràmetres (pesos i biaixos) que s’entrenaran.
Aquest pas defineix l’arquitectura del model, i pot implementar-se a PyTorch:
import torch
import torch.nn as nn
class ThreeLayerNN(nn.Module):
def __init__(self):
super().__init__()
# Arquitectura: 64 → 25 → 15 → 1
self.hidden1 = nn.Linear(64, 25) # Primera capa oculta
self.hidden2 = nn.Linear(25, 15) # Segona capa oculta
self.output = nn.Linear(15, 1) # Capa de sortida
def forward(self, x):
x = torch.sigmoid(self.hidden1(x)) # Activació capa oculta 1
x = torch.sigmoid(self.hidden2(x)) # Activació capa oculta 2
x = torch.sigmoid(self.output(x)) # Activació sortida (probabilitat)
return x
model = ThreeLayerNN()
El mètode __init__ crea les capes i el mètode forward es crida quan s’utilitza el model com una funció per a calcular les activacions a partir d’un tensor d’entrada.
Aquesta xarxa calcula la sortida de la forma:
\[ \hat{y} = \sigma(W^{(2)} \cdot \sigma(W^{(1)}x + b^{(1)}) + b^{(2)}) \]
on \(\sigma\) és la funció sigmoide.
Definició de la funció de pèrdua (loss) i el cost
- Funció de pèrdua: mesura l’error entre la sortida predita \(\hat{y}\) i la real \(y\), per una mostra.
- Cost: és la mitjana de la pèrdua sobre totes les mostres del lot o conjunt d’entrenament.
Per a classificació binària, utilitzem Binary Cross-Entropy (BCE):
\[ L(y, \hat{y}) = -[y \log(\hat{y}) + (1-y) \log(1-\hat{y})] \]
Aquesta funció penalitza més les prediccions molt errònies.
Hi ha dues maneres de calcular aquesta pèrdua en PyTorch, depenent de si el model retorna probabilitats (després del sigmoid) o valors crus (abans del sigmoid, anomenats logits):
# Opció 1: Si el model aplica sigmoid a la sortida
loss_fn = nn.BCELoss()
# Opció 2 (RECOMANADA): Si el model retorna logits (sense sigmoid)
# Aquesta opció és més estable numèricament
loss_fn = nn.BCEWithLogitsLoss()
Què són els logits? Els logits són les sortides crues de la xarxa abans d’aplicar la funció d’activació sigmoid. Utilitzar BCEWithLogitsLoss és més estable numèricament perquè combina el sigmoid i el càlcul de la pèrdua en una sola operació optimitzada, evitant problemes de precisió numèrica.
Entrenament per minimitzar el cost
L’entrenament d’una xarxa neuronal passa per una seqüència de passos que es repeteixen moltes vegades per tal que la xarxa aprengui a fer bones prediccions.
Per a implementar-ho, les llibreries modernes de deep learning utilitzen un mecanisme anomenat diferenciació automàtica que es basa en la construcció d’un graf computacional. Aquest mecanisme s’explica en detall a la secció Grafs computacionals i diferenciació automàtica.
Els passos de l’entrenament són:
-
Passada cap endavant (forward pass)
A partir d’una entrada \(x\), la xarxa calcula una predicció \(\hat{y}\), passant la informació capa per capa fins a la sortida. Cada capa transforma la informació amb pesos, sumes i funcions d’activació.
-
Càlcul de la pèrdua (loss)
Es compara la predicció \(\hat{y}\) amb el valor real \(y\). La diferència entre aquests dos valors ens indica com n’ha estat de dolenta (o de bona) la predicció. Aquesta diferència s’expressa amb una funció de pèrdua (com ara l’error quadràtic o la cross-entropy).
-
Passada cap enrere (backward pass o retropropagació)
Aquest pas serveix per aprendre dels errors. Un cop sabem com de malament ho ha fet la xarxa (la pèrdua), volem saber quin pes ha tingut la culpa i com canviar-lo.
La retropropagació calcula, pas a pas i de dreta a esquerra (de la sortida cap a l’entrada), com cada pes ha contribuït a l’error final. Això es fa amb derivades parcials, que ens indiquen si hem de pujar o baixar cada pes per millorar la predicció.
És com si la xarxa es preguntés:
“Si canviés una mica aquest pes… l’error milloraria o empitjoraria?”
Amb això, la xarxa aprèn a corregir-se sola.
-
Actualització dels pesos (optimitzador)
Un algoritme d’optimització (com el descens del gradient o Adam) ajusta els pesos una mica, en la direcció que redueixi l’error. Aquesta actualització es fa segons la fórmula:
\[ w := w - \alpha \frac{\partial L}{\partial w} \]
On:
- \(w\) és un pes de la xarxa
- \(L\) és la pèrdua
- \(\alpha\) és la taxa d’aprenentatge (learning rate)
La taxa d’aprenentatge controla la mida dels passos durant l’optimització:
- Massa gran → la xarxa no convergeix, oscil·la
- Massa petita → l’entrenament és molt lent
- Valor típic inicial: entre 0.001 i 0.1
Aquest procés es repeteix per cada mostra d’entrenament o per cada mini-batch (petit grup de mostres), i durant moltes èpoques (passades senceres per tot el conjunt d’entrenament).
Durant l’entrenament, és important separar les dades:
- Conjunt d’entrenament: per ajustar els pesos
- Conjunt de validació: per avaluar el rendiment sense sobreajustament
Per a una avaluació més robusta del model, especialment quan el dataset és petit, es pot utilitzar K-Fold Cross-Validation.
Variants de Gradient Descent
Hi ha tres maneres principals d’entrenar una xarxa neuronal, que difereixen en quantes mostres s’utilitzen per calcular el gradient abans d’actualitzar els pesos:
1. Batch Gradient Descent (GD complet)
Utilitza tot el dataset per calcular el gradient i actualitzar els pesos un cop per època.
# Dades d'exemple: X_train shape (num_samples, 64), y_train shape (num_samples, 1)
loss_fn = nn.BCEWithLogitsLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(1000):
model.train()
logits = model(X_train) # Prediccions: (num_samples, 1)
loss = loss_fn(logits, y_train)
optimizer.zero_grad()
loss.backward() # utilitza els gradients calculats
optimizer.step() # 1 actualització per època
if epoch % 100 == 0:
model.eval()
with torch.no_grad(): # desactiva càlcul de gradients
logits_test = model(X_test)
test_loss = loss_fn(logits_test, y_test)
print(f"Epoch {epoch}: Train Loss = {loss.item():.4f}, Test Loss = {test_loss.item():.4f}")
Avantatges: Gradient precís, convergència estable Inconvenients: Lent, requereix molta memòria, pot quedar atrapat en mínims locals
2. Mini-batch Gradient Descent (recomanat)
Divideix el dataset en grups petits (mini-batches) i actualitza els pesos després de cada grup. És l’enfocament més utilitzat en la pràctica.
En l’entrenament amb mini-batches:
- Una època (epoch) processa tot el conjunt d’entrenament
- Cada època es divideix en mini-batches (grups típicament de 16-512 mostres)
- Els pesos s’actualitzen un cop per mini-batch, després de calcular el gradient promig de les mostres del grup
Per exemple, amb 1000 mostres i batch_size=100:
- Cada època té 10 mini-batches
- Hi ha 10 actualitzacions de pesos per època
- Amb 100 èpoques → 1000 actualitzacions totals
from torch.utils.data import DataLoader, TensorDataset
loss_fn = nn.BCEWithLogitsLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
dataset = TensorDataset(X_train, y_train)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
for epoch in range(1000):
model.train()
for X_batch, y_batch in loader:
logits = model(X_batch)
loss = loss_fn(logits, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step() # múltiples actualitzacions per època
En aquest exemple, si el dataset tingués 10 mostres i batch_size=2:
- Cada època processa 10 mostres en 5 mini-batches de 2 mostres
- Hi ha 5 actualitzacions de pesos per època
- Amb 1000 èpoques → 5000 actualitzacions totals
Això coincideix amb l’estructura del codi: el bucle extern (for epoch) es repeteix 1000 vegades, i el bucle intern (for X_batch, y_batch) fa 5 iteracions per època.
Avantatges: Equilibra velocitat (paral·lelització GPU), estabilitat (gradient més suau que mostra individual) i eficiència de memòria (millor que processar tot el dataset alhora) Inconvenients: Requereix ajustar un hiperparàmetre addicional (batch_size)
3. Stochastic Gradient Descent (SGD pur)
Actualitza els pesos després de cada mostra individual (batch_size=1).
from torch.utils.data import DataLoader, TensorDataset
loss_fn = nn.BCEWithLogitsLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
dataset = TensorDataset(X_train, y_train)
loader = DataLoader(dataset, batch_size=1, shuffle=True)
for epoch in range(1000):
model.train()
for X_sample, y_sample in loader:
logits = model(X_sample)
loss = loss_fn(logits, y_sample)
optimizer.zero_grad()
loss.backward()
optimizer.step() # 1 actualització per mostra
Amb 10 mostres i batch_size=1:
- Cada època fa 10 actualitzacions de pesos
- Amb 1000 èpoques → 10000 actualitzacions totals
Avantatges: Actualitzacions freqüents, pot escapar de mínims locals, baixa memòria Inconvenients: Gradient molt sorollós, convergència inestable, difícil aprofitar paral·lelització GPU
Nota: Tot i que l’optimitzador de PyTorch es diu torch.optim.SGD, en realitat és el nom genèric per a gradient descent i es pot usar amb qualsevol dels tres mètodes segons el batch_size que triem.
Comparació de les tres variants:
| Criteri | Batch GD | Mini-batch GD | Stochastic GD |
|---|---|---|---|
| Batch size | Tot el dataset | 16-512 mostres | 1 mostra |
| Actualitzacions/època (1000 mostres) | 1 | ~3-60 | 1000 |
| Qualitat del gradient | Molt precís | Prou precís | Sorollós |
| Velocitat de convergència | Lenta | Ràpida | Variable |
| Ús de memòria | Molt alt | Moderat | Molt baix |
| Paral·lelització GPU | Bona | Excel·lent | Dolenta |
| Capacitat d’escapar de mínims locals | Baixa | Mitjana | Alta |
| Estabilitat | Molt estable | Estable | Inestable |
| Ús pràctic | Poc recomanat | Recomanat | Poc recomanat |
La taula mostra per què mini-batch GD és el mètode més utilitzat: equilibra el nombre d’actualitzacions per època amb l’eficiència computacional i l’estabilitat de l’entrenament.
Modes d’entrenament i avaluació
PyTorch permet canviar el comportament del model segons si estem entrenant o avaluant. Això és important perquè algunes capes especialitzades (com Dropout, que desactiva neurones aleatòriament, o BatchNorm, que normalitza activacions) es comporten de manera diferent en cada mode.
model.train() i model.eval()
PyTorch distingeix entre dos modes d’operació:
model.train(): activa Dropout i BatchNorm, necessari durant l’entrenament.model.eval(): desactiva Dropout i BatchNorm per fer prediccions deterministes.
És una bona pràctica usar sempre aquests modes, fins i tot si el model no té aquestes capes.
# Entrenament
model.train()
for epoch in range(100):
optimizer.zero_grad()
logits = model(X_train)
loss = loss_fn(logits, y_train)
loss.backward()
optimizer.step()
# Avaluació
model.eval()
with torch.no_grad():
logits = model(X_test)
accuracy = (logits.argmax(dim=1) == y_test).float().mean()
torch.no_grad()
Desactiva el seguiment de gradients (el graf computacional) durant l’avaluació (forward pass), estalviant memòria i temps. Per tant, no es podria fer el backward pass (càlcul de gradients). Diferència clau: model.eval() canvia el comportament de capes (Dropout, BatchNorm), mentre que torch.no_grad() només desactiva gradients. Usa’ls junts durant l’avaluació.
Funcions d’activació
Les funcions d’activació determinen com una neurona transforma la seva entrada en una sortida. La tria de la funció adequada és crucial per al rendiment de la xarxa.
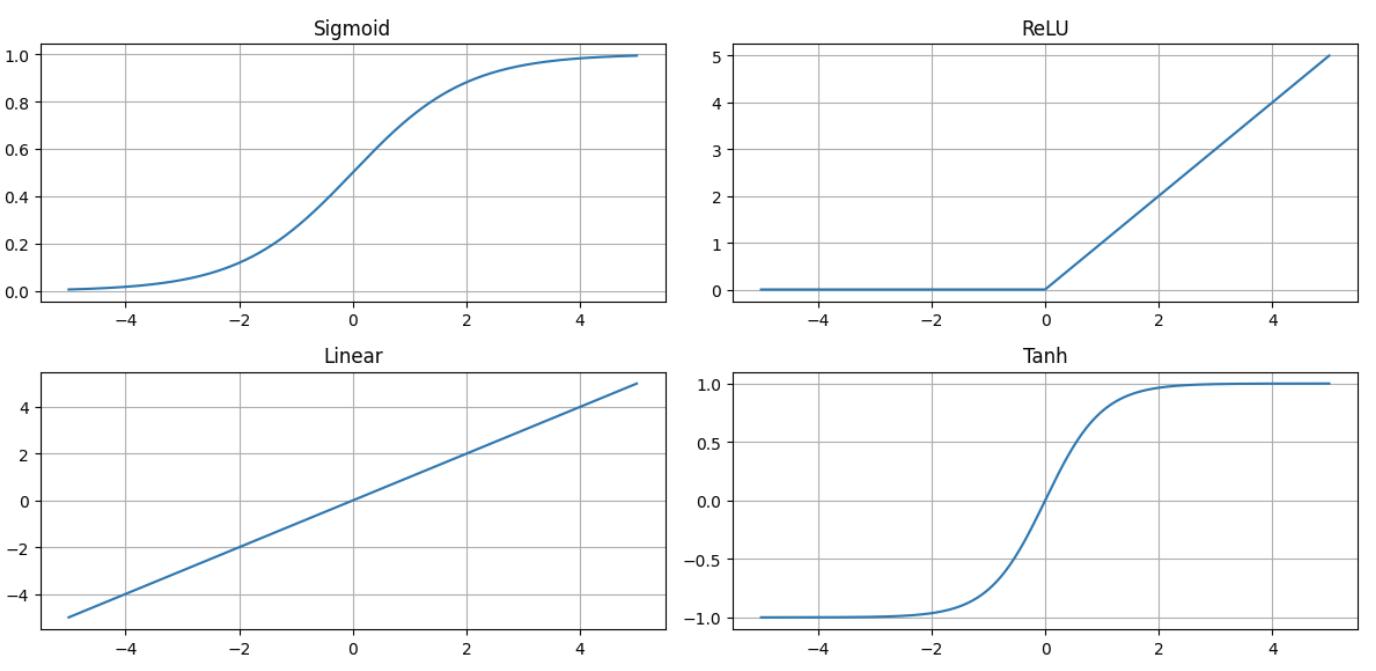
Funcions d’activació més comunes
Fins ara hem utilitzat la funció sigmoide a la capa de sortida per a classificació binària, ja que retorna valors entre 0 i 1 interpretables com a probabilitats. Tanmateix, per a les capes ocultes, la sigmoide presenta problemes importants (saturació i gradient que desapareix).
La funció d’activació més utilitzada en capes ocultes és la ReLU (Rectified Linear Unit):
\[ g(z) = \max(0, z) \]
Aquesta funció retorna 0 si \( z < 0 \), i retorna \( z \) si \( z \geq 0 \). És molt més ràpida de calcular que la sigmoide i evita el problema del gradient que desapareix.
Altres funcions d’activació comunes són:
- Funció lineal o identitat: \(g(z) = z\). S’utilitza a la capa de sortida per a regressió, permetent qualsevol valor real.
- Softmax: transforma un vector de valors reals en una distribució de probabilitats que sumen 1. S’utilitza a la capa de sortida per a classificació multiclasse.
Com triar la funció d’activació
Comencem pel cas de la capa de sortida:
Depenent del tipus de variable objectiu \( y \), hi ha una elecció natural per a la funció d’activació:
- 🔹 Classificació binària → usa sigmoide
- 🔹 Regressió amb valors positius i negatius (p.ex. variació del valor d’una acció) → usa funció lineal
- 🔹 Regressió amb només valors positius (p.ex. predicció del preu d’un habitatge) → usa ReLU
- 🔹 Classificació multiclasse → usa softmax
I les capes ocultes?
Per a les capes ocultes, la funció d’activació més habitual és ReLU. Els motius són:
- Més ràpida de calcular que la sigmoide.
- Evita problemes de gradients molt petits: la sigmoide s’aplana tant a l’esquerra com a la dreta del gràfic (quan \( z \to -\infty \) o \( z \to \infty \)), fent que la seva derivada sigui gairebé zero. Això provoca que els pesos s’actualitzin molt lentament durant la retropropagació, especialment en xarxes profundes.
- Problema potencial de ReLU: si moltes neurones aprenen pesos que produeixen \(z < 0\) constantment, la seva sortida serà sempre 0 i deixaran d’aprendre (neurones “mortes”). Variants com Leaky ReLU solucionen aquest problema.
Cal evitar usar la funció lineal a les capes ocultes, perquè llavors la nostra xarxa no aprendrà res més enllà d’una regressió lineal.
Per tant, ReLU és la millor opció inicial per a capes ocultes, tot i que hi ha altres alternatives com Leaky ReLU, ELU, o tanh, segons el context del problema.
Exemple de classificació binària amb ReLU
import torch
import torch.nn as nn
import torch.nn.functional as F
class BinaryClassificationNN(nn.Module):
def __init__(self):
super().__init__()
# Arquitectura: 64 → 25 → 15 → 1
self.hidden1 = nn.Linear(64, 25) # Primera capa oculta
self.hidden2 = nn.Linear(25, 15) # Segona capa oculta
self.output = nn.Linear(15, 1) # Capa de sortida
def forward(self, x):
x = F.relu(self.hidden1(x)) # ReLU a capa oculta 1
x = F.relu(self.hidden2(x)) # ReLU a capa oculta 2
x = self.output(x) # Retorna logits (sense sigmoid)
return x
model = BinaryClassificationNN()
loss_fn = nn.BCEWithLogitsLoss() # aplica sigmoid internament
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# Entrenament (simplificat)
for epoch in range(100):
model.train()
optimizer.zero_grad()
logits = model(X_train)
loss = loss_fn(logits, y_train)
loss.backward()
optimizer.step()
# Avaluació
model.eval()
with torch.no_grad():
logits = model(X_test) # Dades de test
y_prob = torch.sigmoid(logits) # Convertim logits a probabilitats
y_pred = (y_prob > 0.5).float() # Threshold a 0.5
accuracy = (y_pred == y_test).float().mean()
print(f"Accuracy: {accuracy:.2%}")
Exemple de regressió amb ReLU
En problemes de regressió, volem predir un valor continu en lloc d’una classe. Per exemple, predir el preu d’un habitatge a partir de les seves característiques.
Diferències clau respecte a la classificació binària:
- Capa de sortida: no apliquem sigmoid ni cap altra funció d’activació (usem funció lineal/identitat)
- Funció de pèrdua: utilitzem MSELoss (Mean Squared Error) en lloc de BCE
- Mètrica d’avaluació: mesurem l’error mitjà en lloc de l’accuracy
import torch
import torch.nn as nn
import torch.nn.functional as F
class RegressionNN(nn.Module):
def __init__(self):
super().__init__()
# Arquitectura: 10 → 25 → 15 → 1
self.hidden1 = nn.Linear(10, 25) # Primera capa oculta
self.hidden2 = nn.Linear(25, 15) # Segona capa oculta
self.output = nn.Linear(15, 1) # Capa de sortida
def forward(self, x):
x = F.relu(self.hidden1(x)) # ReLU a capa oculta 1
x = F.relu(self.hidden2(x)) # ReLU a capa oculta 2
x = self.output(x) # Sortida lineal (sense activació)
return x
model = RegressionNN()
loss_fn = nn.MSELoss() # Mean Squared Error
optimizer = optim.SGD(model.parameters(), lr=0.1)
# Entrenament (simplificat)
for epoch in range(100):
model.train()
optimizer.zero_grad()
y_pred = model(X_train)
loss = loss_fn(y_pred, y_train)
loss.backward()
optimizer.step()
# Avaluació
model.eval()
with torch.no_grad():
y_pred = model(X_test)
mae = torch.abs(y_pred - y_test).mean()
print(f"MAE: {mae.item():.4f}")
Notes importants sobre regressió:
- Si els valors de sortida són sempre positius (com preus), es pot utilitzar ReLU a la capa de sortida en lloc de la funció lineal
- Si els valors poden ser positius i negatius, cal utilitzar la funció lineal (identitat) a la sortida
- És recomanable normalitzar les dades d’entrada i sortida per millorar la convergència
Resum
| Funció | Rang | Ús típic | Avantatge clau | Desavantatge |
|---|---|---|---|---|
| Sigmoid | (0, 1) | Capa de sortida (classificació binària) | Interpretable com a probabilitat | Saturació → vanishing gradient |
| ReLU | [0, ∞) | Capa oculta | Senzilla i eficient, evita saturació | Pot causar neurones mortes |
| Leaky ReLU | (-∞, ∞) | Capa oculta | Evita neurones mortes | Pot introduir soroll si la pendent negativa és massa alta |
| Tanh | (-1, 1) | Capa oculta | Centrada en zero, útil per dades normalitzades | Saturació → vanishing gradient |
| Lineal (Identitat) | (-∞, ∞) | Capa de sortida (regressió) | Manté escala i signe de la sortida | No introdueix no-linealitat |
| Softmax | (0, 1), ∑ = 1 | Capa de sortida (classificació multi-classe) | Distribució de probabilitats sobre classes | Cost computacional més alt |
Classificació multiclasse
La regressió logística és una tècnica adequada per a problemes de classificació binària, és a dir, quan només hi ha dues classes possibles.
Quan treballem amb múltiples classes, necessitem aprendre una frontera de decisió que separi totes les classes. En aquest cas, utilitzem la regressió softmax, una generalització de la regressió logística que permet afrontar problemes de classificació multiclasse.
En classificació binària tenim 1 sortida: “probabilitat que sigui de classe 1”.
En classificació multiclasse necessitem N sortides (una per cada classe). Per exemple, per reconèixer dígits (0-9) necessitem 10 sortides.
El problema: volem que aquestes 10 sortides representin probabilitats que sumin 1.
Exemple concret:
- Entrada: imatge d’un “3” escrit a mà
- Logits (sortides abans de softmax): [0.1, -0.5, 0.3, 4.2, 0.8, -1.0, 0.2, -0.3, 0.5, 0.1]
- Després de softmax: [0.02, 0.01, 0.03, 0.85, 0.04, 0.01, 0.02, 0.01, 0.03, 0.02]
- Interpretació: 85% de confiança que és un “3”, 4% que és un “4”, etc.
Què fa softmax?
- Converteix valors arbitraris (logits) en probabilitats (entre 0 i 1)
- Garanteix que totes les probabilitats sumin exactament 1
- Els valors més alts (logits) es converteixen en probabilitats més altes
Fonaments matemàtics
Suposem que la variable objectiu \(y\) pot prendre els valors \(1, 2, 3, \ldots, N\). Definim:
\[ z_j = \hat{\mathbf{w}}_j \cdot \hat{\mathbf{x}} + b_j, \quad j = 1, \ldots, N \]
on:
- \(\hat{\mathbf{x}}\) és el vector d’entrada (amb el biaix inclòs si cal),
- \(\hat{\mathbf{w}}_j\) són els pesos associats a la classe \(j\),
- \(b_j\) és el biaix corresponent a la classe \(j\).
La funció d’activació softmax per a la classe \(j\) es defineix com:
\[ a_j = \frac{e^{z_j}}{\sum\limits_{k=1}^{N} e^{z_k}} = P(y = j ,|, \hat{\mathbf{x}}) \]
Aquesta expressió garanteix que:
\[ a_1 + a_2 + \ldots + a_N = 1 \]
Per tant, cada \(a_j\) es pot interpretar com la probabilitat que la mostra pertanyi a la classe \(j\).
Funció de pèrdua
La funció de pèrdua utilitzada és l’entropia creuada:
\[ \text{loss} = -\log(a_j) \quad \text{si } y = j \]
És a dir, només es penalitza la probabilitat assignada a la classe correcta.
Una capa softmax és especial perquè el càlcul de les seves activacions depèn de tots els valors \(z_j\) simultàniament. En classificació binària, cada neurona tenia una sortida independent. En canvi, en classificació multiclasse, el càlcul de cada \(a_j\) es fa en relació amb totes les altres sortides. Aquesta normalització fa que la sortida sigui una distribució de probabilitat sobre les classes possibles.
Consideracions en PyTorch
En problemes de classificació multiclasse amb PyTorch, és habitual utilitzar nn.CrossEntropyLoss. Cal tenir en compte:
- El model ha de retornar els logits, és a dir, els valors \(z\) abans d’aplicar softmax.
Els logits són les puntuacions no normalitzades que surten de l’última capa (
Linear) del model. - No s’ha d’aplicar
softmaxdins del mètodeforward, ja queCrossEntropyLossja l’aplica de forma interna, eficient i estable.
Per què és millor no aplicar softmax manualment?
Calcular softmax i després log pot generar problemes de precisió numèrica, sobretot quan les probabilitats són molt petites. PyTorch optimitza aquest procés per evitar aquest tipus d’errors.
Exemple: dígits manuscrits
Per exemple, en el cas de la classificació de dígits manuscrits (de 0 a 9), treballem amb 10 classes.
L’última capa del nostre model deixarà de tenir una sola unitat (com en la classificació binària) i en tindrà 10, una per cada dígit. Aquesta última capa seria una capa softmax.
# Definir el model
class MulticlassNN(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(64, 25)
self.fc2 = nn.Linear(25, 15)
self.output = nn.Linear(15, 10) # 10 classes
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.output(x) # No softmax here!
return x
model = MulticlassNN()
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
# Entrenament (simplificat)
for epoch in range(100):
model.train()
optimizer.zero_grad()
logits = model(X_train)
loss = loss_fn(logits, y_train)
loss.backward()
optimizer.step()
# Avaluació
model.eval()
with torch.no_grad():
logits = model(X_test)
y_pred = torch.argmax(logits, dim=1)
accuracy = (y_pred == y_test).float().mean()
print(f"Accuracy: {accuracy:.2%}")
Classificació multietiqueta (multilabel)
En aquest tipus de problemes, una sola entrada pot estar associada a diverses etiquetes binàries. Per tant, la variable objectiu \(\mathbf{y}\) és un vector de \(N\) possibles etiquetes, cadascun dels quals pot ser 0 o 1.
Una estratègia possible per abordar aquest problema seria construir \(N\) xarxes neuronals independents, una per a cada etiqueta. No obstant això, hi ha una alternativa més eficient: entrenar una sola xarxa amb \(N\) sortides.
En aquest cas:
- L’última capa tindrà \(N\) unitats de sortida.
- Cada unitat aplica una funció d’activació sigmoide.
- Això permet que cada sortida \(\hat{y}_j\) representi la probabilitat que l’etiqueta \(j\) estigui present (valgui 1), de manera independent de les altres.
Aquest enfocament aprofita el fet que, tot i que les etiquetes són múltiples, no són mútuament excloents, i per tant no cal una normalització com la que fa softmax.
class MultiLabelNN(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(100, 64)
self.fc2 = nn.Linear(64, 32)
self.output = nn.Linear(32, 5) # 5 sortides, 1 per etiqueta
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.output(x) # Logits (NO sigmoid aquí)
return x
# Exemple: 5 etiquetes (Acció, Sci-fi, Drama, Comèdia, Terror)
model = MultiLabelNN()
loss_fn = nn.BCEWithLogitsLoss() # (sigmoid + BCE combinats)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# Entrenament (simplificat)
for epoch in range(100):
model.train()
optimizer.zero_grad()
logits = model(X)
loss = loss_fn(logits, y)
loss.backward()
optimizer.step()
# Avaluació
model.eval()
with torch.no_grad():
logits = model(X[:5])
y_prob = torch.sigmoid(logits)
y_pred = (y_prob > 0.5).float()
print(f"Predicció: {y_pred[0]}")
print(f"Real: {y[0]}")
Pytorch per tipus de problema
A continuació es mostren cadascun dels tipus de problemes vistos i els aspectes específics que cal considerar.
| Aspecte | Classificació Binària | Classificació Multiclasse | Classificació Multilabel | Regressió |
|---|---|---|---|---|
| Capa de Sortida | 1 neurona | C neurones | C neurones | 1 neurona (o més) |
| Activació a la Sortida | Cap (logits) | Cap (logits) | Cap (logits) | Cap (lineal) |
| Funció de Pèrdua | nn.BCEWithLogitsLoss() | nn.CrossEntropyLoss() | nn.BCEWithLogitsLoss() | nn.MSELoss() o nn.L1Loss() |
| Format Targets | [batch, 1] float (0.0 o 1.0) | [batch] long (índexs) | [batch, C] float (0s i 1s) | [batch, 1] float (continus) |
| Com fer Prediccions | torch.sigmoid(output) > 0.5 | torch.argmax(output, dim=1) | torch.sigmoid(output) > 0.5 | output directament |
| Com obtenir Probabilitats | torch.sigmoid(output) | F.softmax(output, dim=1) | torch.sigmoid(output) | N/A |
| Exemple Target | [1.0] (classe positiva) | 2 (classe índex 2) | [0, 1, 1, 0] (labels 1 i 2) | [23.5] (valor continu) |
Optimització avançada
El descens de gradient és un mètode per trobar el mínim de la funció de cost fent passos de mida \(\alpha\) (la taxa d’aprenentatge). L’actualització d’un pes \(w_j\) en un sol pas es formula com:
\[ w_j := w_j - \alpha \frac{\partial J}{\partial w_j} \]
On:
- \(\alpha\) (learning rate) controla la mida del pas.
- \(\frac{\partial J}{\partial w_j}\) és la derivada de la funció de cost respecte al pes \(w_j\).
Si tots els passos van en la mateixa direcció, podríem augmentar \(\alpha\) per accelerar la convergència. Tanmateix, un pas massa gran pot provocar oscil·lacions o divergència.
Adam (Adaptive Moment Estimation) és un algorisme que ajusta automàticament la taxa d’aprenentatge per a cada paràmetre (pesos i biaixos). Això permet:
- Augmentar la taxa d’aprenentatge si els passos són petits i consistents.
- Reduir la taxa d’aprenentatge si hi ha oscil·lacions per salts massa grans.
Per canviar l’optimitzador a Adam utilitzant PyTorch, només cal substituir optim.SGD per optim.Adam:
# Abans (SGD):
optimizer = optim.SGD(model.parameters(), lr=0.1)
# Després (Adam):
# Adam necessita una learning rate més petita que SGD (típicament 1e-3 o 1e-4)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
Important: Adam sol necessitar una taxa d’aprenentatge molt més petita que SGD. Si utilitzes lr=0.1 amb Adam, l’entrenament probablement divergirà. Els valors típics per Adam són 1e-3 (0.001) o 1e-4 (0.0001).
Adam és una excel·lent elecció per defecte a l’hora d’optimitzar xarxes neuronals gràcies a la seva capacitat d’adaptar la taxa d’aprenentatge durant l’entrenament.
Grafs computacionals i diferenciació automàtica
Les llibreries modernes de deep learning (com PyTorch o TensorFlow) utilitzen un mecanisme anomenat diferenciació automàtica (automatic differentiation o autograd). Aquest mecanisme es basa en la construcció d’un graf computacional.
Què és un graf computacional?
Un graf computacional és una representació interna que la llibreria crea automàticament mentre es fan càlculs. Està format per:
- Nodes: representen les operacions matemàtiques (multiplicacions, sumes, funcions d’activació)
- Arestes: connecten les operacions seguint l’ordre en què s’executen
Aquest graf registra totes les operacions que es fan sobre els tensors durant la passada cap endavant, com ara:
- Transformacions lineals (multiplicacions de matrius i sumes)
- Funcions d’activació (ReLU, sigmoid, tanh, etc.)
- Funcions de pèrdua (cross-entropy, MSE, etc.)
El més important és que també emmagatzema com calcular les derivades de cada operació.
Per què serveix el graf computacional?
El graf s’utilitza en dos moments diferents de l’entrenament:
-
Passada endavant (forward pass): mentre calculem la predicció, el graf es va construint automàticament, registrant cada operació.
-
Passada enrere (backward pass): quan volem aprendre dels errors, el graf es recorre en sentit invers per calcular les derivades de forma automàtica, sense que nosaltres les hàgim de programar manualment.
Aquest procés automàtic de calcular derivades s’anomena diferenciació automàtica, i és el que fa possible entrenar xarxes neuronals amb milions de paràmetres sense haver de calcular derivades a mà.
Com funciona la diferenciació automàtica?
Durant l’entrenament, els tensors (les estructures de dades que contenen els pesos i les dades) tenen la capacitat de “recordar” totes les operacions que s’han fet sobre ells. Quan arribem al final i tenim la pèrdua calculada, podem demanar a la llibreria que calculi automàticament les derivades de la pèrdua respecte a cada pes de la xarxa.
Això ho fa aplicant la regla de la cadena del càlcul diferencial de forma automàtica: va descomponent les derivades complexes en derivades simples d’operacions bàsiques (suma, multiplicació, funcions d’activació), i les combina per obtenir el gradient de cada paràmetre.
En resum: els tensors diferencien totes les funcions que s’han executat durant la passada cap endavant (forward pass), però ho fan durant la passada cap enrere (backward pass), recorrent el graf computacional en sentit invers.
El resultat: sabem exactament quant hem d’ajustar cada pes per reduir l’error, sense haver de derivar ni una sola equació manualment.
La clau de l’entrenament modern de xarxes neuronals és aquesta diferenciació automàtica: el càlcul automàtic de derivades mitjançant el graf computacional. Això permet entrenar models amb milions de paràmetres sense haver d’escriure ni una sola derivada a mà.
L’arquitectura Transformer i els LLMs
Les arquitectures vistes en aquest document (MLP, CNN) són la base matemàtica del deep learning modern, però a partir de 2017 l’arquitectura Transformer va passar a dominar el camp, especialment en text i llenguatge. Tots els LLMs actuals (GPT, Llama, Gemini…) són Transformers. Els conceptes d’aquesta secció (propagació, retropropagació, activacions, optimitzadors) continuen sent els fonaments sobre els quals s’assenten. Els detalls del Transformer en si es cobreixen a Sistemes LLM Aplicats.
Capes convolucionals
Fins ara hem treballat amb capes totalment connectades (dense layers), on cada neurona està connectada a totes les sortides de la capa anterior. Aquest enfocament funciona bé per a moltes tasques, però quan treballem amb dades estructurades com imatges o senyals temporals, hi ha un tipus de capa més eficient: les capes convolucionals.
Una capa convolucional és una capa especial on cada neurona només “veu” una regió local de l’entrada procedent de la capa anterior. Això significa que, en lloc d’estar connectada a totes les sortides anteriors, cada neurona aplica un petit filtre (o kernel) a una finestra reduïda de valors.
Avantatges:
-
Càlcul més ràpid
Com que cada neurona processa només una part de l’entrada, es redueix el nombre de connexions i, per tant, la quantitat de càlcul necessari. -
Menys dades d’entrenament i menor sobreajustament
Els filtres locals comparteixen pesos, de manera que el model té menys paràmetres i resulta menys procliu a memoritzar dades específiques.
Quan encadenem diverses capes convolucionals en una xarxa, obtenim una xarxa neuronal convolucional (CNN), que és especialment eficaç per al processament d’imatges i sèries temporals.
Exemple pràctic (1D): suposem que tenim un senyal d’ECG d’1 dimensió amb 100 punts d’entrada: \(x_1, x_2, \dots, x_{100}\).
-
Primera capa oculta
Utilitza un filtre de grandària 20 i pas (stride) de 10 per generar 9 activacions. Cada activació processa finestres des de \(x_1\dots x_{20}\), \(x_{11}\dots x_{30}\), \(x_{21}\dots x_{40}\), etc. -
Segona capa oculta
Aplica un filtre de grandària 5 i pas de 2 sobre les 9 activacions anteriors per obtenir 3 noves activacions, que corresponen a les finestres \(a_1\dots a_5\), \(a_3\dots a_7\) i \(a_5\dots a_9\). -
Capa de sortida
Acaba amb una funció sigmoide que retorna la probabilitat de presència o absència de malaltia cardíaca.
Aquest procés permet que la xarxa detecti patrons locals (per exemple, formes d’ones característiques de l’ECG) i els combini progressivament per fer una classificació robusta.
Càlcul eficient per a xarxes neuronals
Quan treballem amb xarxes neuronals, el càlcul de la inferència pot ser molt costós si es fa mostra per mostra i neurona per neurona. Per això utilitzem biblioteques optimitzades que aprofiten el maquinari modern.
A continuació t’expliquem les principals tecnologies implicades.
BLAS (Basic Linear Algebra Subprograms)
És una especificació estàndard de rutines bàsiques d’àlgebra lineal (com multiplicacions de matrius i vectors).
- Funciona en CPU
- Les seves implementacions (com OpenBLAS, MKL, ATLAS…) són molt optimitzades
- És la base de moltes biblioteques científiques (
NumPy,SciPy, etc.)
Exemple: multiplicar dues matrius grans amb numpy.dot() utilitza BLAS per fer-ho ràpidament.
GPU (Graphics Processing Unit)
Una GPU és un processador paral·lel que pot executar milers de càlculs al mateix temps. Tot i que es va dissenyar per a gràfics, avui s’utilitza àmpliament per a càlcul científic i d’IA.
- Té milers de nuclis simples (en comparació amb pocs nuclis potents d’una CPU)
- Ideal per a càlculs repetitius i paral·lels com els de l’àlgebra lineal
CUDA (Compute Unified Device Architecture)
És la plataforma de programació creada per NVIDIA per desenvolupar aplicacions que s’executin a les seves GPU.
- Permet escriure codi que s’executa directament dins la GPU
- Exposa una API per controlar memòria, fils d’execució, etc.
- Moltes biblioteques populars (com PyTorch o TensorFlow) fan servir CUDA per sota si hi ha GPU disponible
cuBLAS (CUDA BLAS)
És la versió de BLAS implementada per NVIDIA per executar-se sobre GPU amb CUDA.
- Té les mateixes operacions que BLAS, però molt més ràpides a la GPU
- L’ús de
torch.matmulotf.matmulen dispositius CUDA utilitza cuBLAS per sota - Aprofita tot el paral·lelisme de la GPU per multiplicar matrius de forma massiva
Resum:
| Tecnologia | Funciona a… | Fa què? | Exemples d’ús |
|---|---|---|---|
| BLAS | CPU | Operacions bàsiques d’àlgebra lineal | numpy.dot, scipy.linalg |
| GPU | Targeta gràfica | Execució massiva de càlculs paral·lels | torch.Tensor.to("cuda") |
| CUDA | GPU NVIDIA | Plataforma per programar GPUs | PyTorch, TensorFlow, numba |
| cuBLAS | GPU NVIDIA | Versió GPU de BLAS | torch.matmul amb CUDA activat |
Aquestes tecnologies són claus per fer que les xarxes neuronals siguin ràpides i escalables. Quan entrenes o fas inferència amb models grans, estar familiaritzat amb aquestes eines t’ajuda a entendre què passa “sota el capó”.
Organització de matrius i dimensions
Per aprofitar aquestes tecnologies d’acceleració, cal entendre com s’organitzen les dades en format matricial.
Dimensions típiques en processament per lots
Suposem que tenim:
- \(m = 3\) mostres d’entrada al lot (batch)
- Cada mostra és un vector d’entrada amb \(n_{\text{in}} = 4\) característiques
- La capa té \(n_{\text{out}} = 2\) neurones
Matriu d’entrada \(X\)
Conté les mostres del lot:
\[ X = \begin{bmatrix} x_{1}^{(1)} & x_{1}^{(2)} & x_{1}^{(3)} \\ x_{2}^{(1)} & x_{2}^{(2)} & x_{2}^{(3)} \\ x_{3}^{(1)} & x_{3}^{(2)} & x_{3}^{(3)} \\ x_{4}^{(1)} & x_{4}^{(2)} & x_{4}^{(3)} \\ \end{bmatrix} \in \mathbb{R}^{4 \times 3} \]
Cada columna és una mostra amb les seves característiques.
Matriu de pesos \(W\)
Cada fila de \(W\) conté els pesos d’una neurona:
\[ W = \begin{bmatrix} w_{1,1} & w_{1,2} & w_{1,3} & w_{1,4} \\ w_{2,1} & w_{2,2} & w_{2,3} & w_{2,4} \\ \end{bmatrix} \in \mathbb{R}^{2 \times 4} \]
Vector de biaixos \(b\)
\[ b = \begin{bmatrix} b_1 \ b_2 \end{bmatrix} \in \mathbb{R}^{2} \]
Càlcul de l’activació lineal \(Z\)
Fem la multiplicació i sumem el biaix:
\[ Z = W \cdot X + b = \begin{bmatrix} z_1^{(1)} & z_1^{(2)} & z_1^{(3)} \\ z_2^{(1)} & z_2^{(2)} & z_2^{(3)} \\ \end{bmatrix} \in \mathbb{R}^{2 \times 3} \]
Cada columna de \(Z\) és la sortida (abans de l’activació) per una mostra.
Resum de dimensions
| Matriu | Dimensions | Significat |
|---|---|---|
| \(X\) | \(n_{\text{in}} \times m\) | Entrades: cada columna és una mostra |
| \(W\) | \(n_{\text{out}} \times n_{\text{in}}\) | Pesos: cada fila correspon a una neurona |
| \(b\) | \(n_{\text{out}}\) | Biaixos: un valor per neurona |
| \(Z\) | \(n_{\text{out}} \times m\) | Activacions lineals: cada columna és l’output per mostra |
El producte \(W \cdot X\) és possible perquè les dimensions coincideixen: \((n_{\text{out}} \times n_{\text{in}}) \cdot (n_{\text{in}} \times m) = (n_{\text{out}} \times m)\).
Transposada d’una matriu
La transposada d’una matriu \(A\), notada \(A^T\), s’obté intercanviant files per columnes:
\[ A = \begin{bmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \end{bmatrix} \quad\Rightarrow\quad A^T = \begin{bmatrix} a_{11} & a_{21} \\ a_{12} & a_{22} \\ a_{13} & a_{23} \end{bmatrix} \]
Si \(A\) és \(m \times n\), llavors \(A^T\) és \(n \times m\).
Ús pràctic: diferents convencions
Algunes biblioteques (com NumPy) representen \(X\) amb forma \(m \times n_{\text{in}}\), és a dir, cada fila és una mostra. En aquest cas, cal fer servir la transposada dels pesos:
\[ Z = X \cdot W^T + b \]
On:
- \(X\) té forma \(m \times n_{\text{in}}\)
- \(W^T\) té forma \(n_{\text{in}} \times n_{\text{out}}\)
- \(Z\) té forma \(m \times n_{\text{out}}\)
Exemple en PyTorch:
import torch
m = 10 # nombre de mostres
n_in = 64 # característiques d'entrada
n_out = 25 # neurones a la capa
# Dades d'entrada (cada fila és una mostra)
X = torch.randn(m, n_in) # (10, 64)
# Pesos i biaixos
W = torch.randn(n_out, n_in) # (25, 64)
b = torch.randn(n_out) # (25,)
# Càlcul vectoritzat per tot el lot
Z = torch.matmul(X, W.T) + b # (10, 25)
# Equivalent: Z = X @ W.T + b
print("Forma de Z:", Z.shape) # torch.Size([10, 25])
Aquest enfocament vectoritzat permet processar moltes mostres simultàniament, aprofitant al màxim les capacitats de BLAS (a CPU) o cuBLAS (a GPU).